Actuarial data science is about actuaries and data scientists working together to turn data into valuable business logic. It’s as simple as that. Or is it? Well, it has been a while since I first had the opportunity to team up with this fascinating creature called a data scientist. I felt impressed and confused at the same time. Why?
I was impressed by the data scientist’s hands-on approach towards data design and data wrangling . Data scientists have fast programming skills in languages such as Python and R. Also, they have the ability to scale their coding quickly towards more powerful computing platforms such as Azure and AWS. And, last but not least, we as actuaries can learn from the data scientist’s “just-do” mentality when it comes to solving data problems, applying many machine-learning techniques.
Data science insights
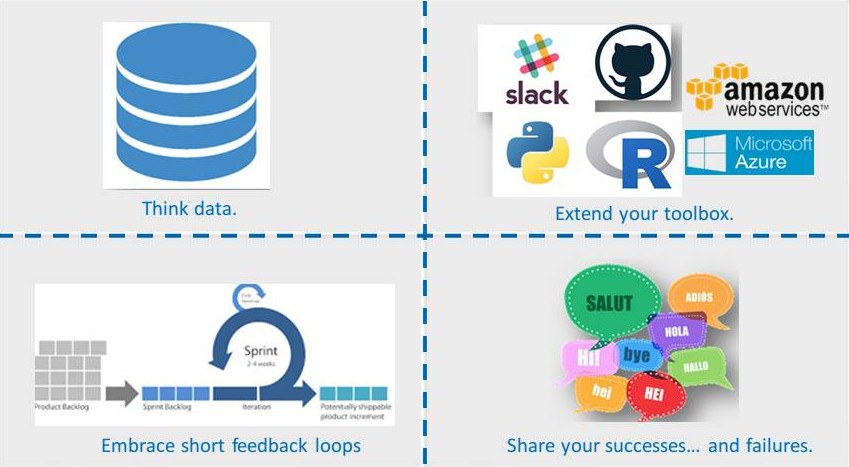
Let’s have a look at the picture below. It summarizes four important insights I learned when working in a multi-disciplinary team with (among others) data scientists and financial professionals.
- Think data. When solving quantitative problems, financial professionals are inclined to consider the job done when they have the formulas right. Data come second. Data scientists, however, prefer a more data centric approach. They always start with the data in mind. They do not only perform regular sanity checks to assure its quality but also have a keen interest in the structure of the data. Also, data play the starring role when it comes to tuning hyper parameters and cross validating predictions.
- Extend your toolbox. If your only tool is a hammer then every problem looks like a nail. Spreadsheet software like Microsoft Excel and Libre Office are flexible tools for performing ad hoc calculations. At many financial institutions and consultancy firms these tools are so ubiquitous that they are basically used for any type of quantitative analysis. However, when it comes to exploring, training, testing, sharing, reproducing and deploying a variety of complex models on large data sets, they fall short. Keeping track of all those changes during the development cycle requires at least hands-on experience with a solid programming language and a distributed version control system.
- Embrace short feedback loops. It’s more often than not that organizations decide to start a data science project to gain new insights or to develop an innovative product. The road that leads to the final answer can be foreseen to a certain extend but will definitely be bumpy at times. This is why development teams tend to split their journey into short intervals, so called “sprints”. The deliverable for the first sprint is clearly defined. Once the first sprint has been finished, a team evaluation takes place. Based on its results, the objectives and deliverables for the next sprint are re(de)fined. The advantage of this approach is that it keeps the process flexible, allowing to make adjustments along the way where needed. As a big bonus, this approach keeps the team motivated as it clearly sees its proto types evolve towards the final product.
- Share your successes … and failures. Financial professionals tend to be a bit reserved when it comes to sharing information with their colleagues and team mates. Data scientists, on the other hand, tend to embrace an atmosphere of openness. Right from the beginning of the project, team member share ideas, code, successes and failures, actively seeking each other out for assistance and input.
Bridging the gap
Working together with data scientists can be confusing at times. First, their vocabulary seems to be packed with fancy words like “deep learning” and “features”. From a statistician’s point of view these are just “multi-layer networks” and “dependent variables”, respectively.
While actuaries feel comfortable defining their model first, data scientists start, well … understanding the data and its structure. When applying parametric models, data scientists tend to be quite pragmatic (some actuaries would rather call it lousy) when it comes to testing the underlying model assumptions.
So where do actuaries and data scientists meet? Actuaries are quite good at pinpointing the questions the data scientist may not want to hear. Do the data justify the chosen model in the first place? In turn, data scientist are very good at implementing the data pipe line as a whole. Yes indeed, actuaries and data scientists together possess the creativity and the quantitative skills to turn data into valuable business logic.
What’s next?
Upcoming articles will feature practical use cases that apply when actuaries and data scientist decide to team up for a project. We will set the scene with some small examples that solve common financial problems using tools that are common within the data science community. Later posts will scale these cases to related domains like algotrading, claim prevention and on-demand insurance, thereby taking up the challenge of bridging the gap between actuarial and data science.