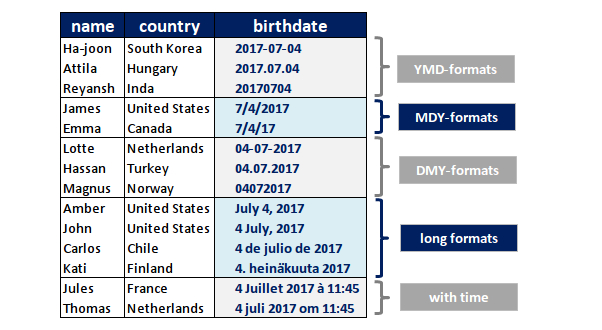
What do these world citizens have in common?
They were all born on U.S. Independence Day last year! As we can see, dates are expressed in different formats around the globe. The order of Year (Y), Month (M) and Day (D) mostly determines how a specific date looks like.
Let’s assume we receive a flat CSV file containing dates formatted according to any of these formats. In this post we will see how each of the birthdates in the table above can be parsed correctly using Pandas’ read_csv() method.
If you want to follow along, here you can find the sample csv files and jupyter notebook I used for this post.
YMD formats
This is my favorite date format by a landslide, as it leaves little room for confusion. If I have the opportunity to create a CSV file myself, I always prefer to use the ISO 8601 format Y-M-D (like in 2017-07-04). Reading CSV files containing YMD date formats is straighforward in Pandas as we can just use the default settings of read_csv() :
import pandas as pd
# Ha-joon: 2017-07-04
df = pd.read_csv("ha-joon.txt", parse_dates=['birthdate'])
# Attila: 2017.07.4
df = pd.read_csv("attila.txt", parse_dates=['birthdate'])
# Reyansh: 20170704
df = pd.read_csv("reyansh.txt", parse_dates=['birthdate'])
MDY formats
Pandas seems to be a bit biased towards common American date formats as these are parsed correctly just using the default parameters:
# James: 7/4/2017
df = pd.read_csv("james.txt", parse_dates=['birthdate'])
# Emma: 7/4/17
df = pd.read_csv("emma.txt", parse_dates=['birthdate'])
DMY formats
These date formats, common in most European countries, require one additional parameter, either “dayfirst” or “date_parse”:
# Lotte: 04-07-2017
df = pd.read_csv("lotte.txt", parse_dates=['birthdate'], dayfirst=True)
# Hassan: 04.07.2017
df = pd.read_csv("hassan.txt", parse_dates=['birthdate'], dayfirst=True)
# Magnus: 04072017
dateparse = lambda x: pd.datetime.strptime(x, '%d%m%Y')
df = pd.read_csv("magnus.txt", parse_dates=['birthdate'], date_parser=dateparse)
Long formats
Long date formats contain the month as a language specific text string. For languages other than English, this format requires one additional parameter “date_parse” and the parse method from the dateparser module:
# Amber: July 4, 2017
df = pd.read_csv("amber.txt", sep=';', parse_dates=['birthdate'])
# John: 4 July 2017
df = pd.read_csv("john.txt", parse_dates=['birthdate'])
import dateparser
# Carlos: 4 de julio de 2017
df = pd.read_csv("carlos.txt", parse_dates=['birthdate'], date_parser=dateparser.parse)
# Kati: 4. heinäkuuta 2017
df = pd.read_csv("kati.txt", parse_dates=['birthdate'], date_parser=dateparser.parse)
Please note that Amber’s date format July 4, 2017 contains a comma. That’s why we changed the seperators between the columns from commas to semicolons, as reflected by the the sep=’;’ setting.
Long formats with timestamp
Long date formats with timestamp require one additional parameter “date_parse” and the parse method from the dateparser module.
import dateparser
# Jules: 4 Juillet 2017 à 11:45
df = pd.read_csv("jules.txt", parse_dates=['birthdate'], date_parser=dateparser.parse)
# Thomas: 4 juli 2017 om 11:45
df = pd.read_csv("thomas.txt", parse_dates=['birthdate'], date_parser=dateparser.parse)
Conclusion: Pandas is smart!
As we have seen in this post, Pandas is pretty smart when it comes to parsing dates in different formats. Only the DMY formats (common in most European countries) and the long month formats (both with and without timestamp) require some non-default parameter settings for “dayfirst” or “date_parse”. In all the other examples, the dates were parsed correctly, just using the default settings from Pandas’ read_csv() method.